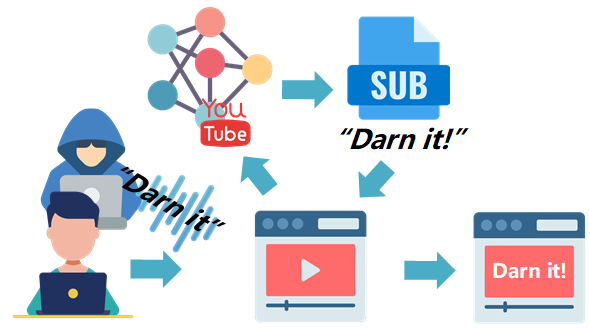
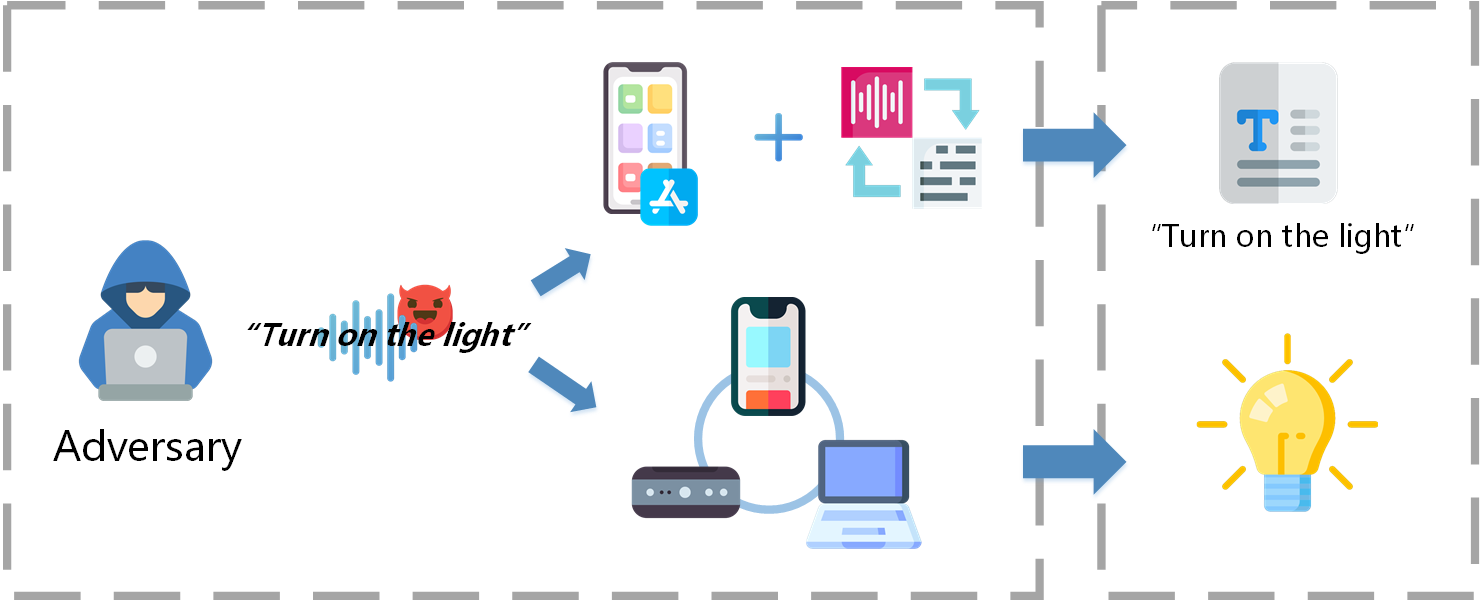
We propose ALIF, the first low-cost attack on black-box ASR using adversarial linguistic features. Based on the ALIF pipeline, we propose ALIF-OTL and ALIF-OTA schemes to launch efficient attacks in the digital domain and in the physical playback environment on four commercial ASRs and voice assistants.
Tips:
★ We recommend listening to all examples before checking out any transcriptions.
| Target APIs | Attack examples | Transcriptions |
| Amazon |
|
|
| Amazon |
|
|
| Azure |
|
|
| Azure |
|
|
| iFLYTEK |
|
|
| iFLYTEK |
|
|
| Tencent |
|
|
| Tencent |
|
We select five sentences and generate audio samples with varying blurring components for each. The audio samples in the second column are created by adding linguistic perturbation only. The subsequent three columns feature audio samples generated using a single blurring component. The final column includes audio samples produced using all blurring components, except for linguistic perturbation.
| commands | Linguistic Perturbation Only | Parameter Beta Only | Parameter Gamma Only | Parameter Alpha Only | All Mel Blurring |
| command1 | |||||
| command2 | |||||
| command3 | |||||
| command4 | |||||
| command5 |
We perform a user study (6 volunteers who evaluated 12 ALIF samples on a 0-4 intelligibility scale and transcribed them). Results show an average intelligibility score of 0.84 and a 78% CER, confirming their incomprehensibility.
| Commands | User 1 | User 2 | User 3 | User 4 | User 5 | User 6 | Average score |
| Airplane mode on | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Call one two three | 0 | 1 | 2 | 1 | 4 | 1 | 1.5 |
| Cancel my alarm clock | 1 | 1 | 1 | 0 | 1 | 0 | 0.67 |
| Darn it | 0 | 1 | 2 | 1 | 0 | 0 | 0.67 |
| I can't take it anymore | 1 | 1 | 1 | 2 | 0 | 1 | 1 |
| I need help | 0 | 1 | 1 | 4 | 1 | 1 | 1.33 |
| Navigate to my office | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Sand a message to my mom | 0 | 1 | 0 | 1 | 0 | 0 | 0.33 |
| Transfer the payment | 1 | 0 | 1 | 2 | 0 | 0 | 0.67 |
| Turn on the light | 0 | 1 | 1 | 4 | 0 | 1 | 1.17 |
| Unlock the door | 1 | 2 | 2 | 1 | 0 | 1 | 1.17 |
| What's the time | 1 | 1 | 1 | 1 | 0 | 0 | 0.67 |
| Commands | User 1 | User 2 | User 3 | User 4 | User 5 | User 6 | Average CER |
| Airplane mode on | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Call one two three | 1 | 0.72 | 0.33 | 0.72 | 0.28 | 0.33 | 0.56 |
| Cancel my alarm clock | 0.57 | 0.86 | 1 | 1 | 0.95 | 1 | 0.9 |
| Darn it | 1 | 0.86 | 1 | 1 | 1 | 1 | 0.98 |
| I can't take it anymore | 0.39 | 0.74 | 0.48 | 0.3 | 1 | 0.48 | 0.57 |
| I need help | 1 | 0.91 | 1 | 0 | 0.91 | 1 | 0.8 |
| Navigate to my office | 0.86 | 0.81 | 1 | 0.67 | 0.67 | 1 | 0.83 |
| Sand a message to my mom | 1 | 0.75 | 1 | 0.79 | 1 | 1 | 0.92 |
| Transfer the payment | 0.4 | 1 | 1 | 0.3 | 1 | 1 | 0.78 |
| Turn on the light | 1 | 0.82 | 0.35 | 0 | 1 | 0.35 | 0.59 |
| Unlock the door | 0.4 | 0.4 | 0.4 | 0.47 | 1 | 0.4 | 0.51 |
| What's the time | 0.87 | 0.8 | 1 | 0.6 | 1 | 1 | 0.88 |
We ablate blurring components and gather volunteers' opinions on the audios. The results confirm that perturbations on linguistic features are the most crucial factor that affects human perception.
| Commands | Linguistic Perturbation Only | Parameter Beta Only | Parameter Gamma Only | Parameter Alpha Only | All Mel Blurring |
| command1 | 2.5 | 3.5 | 3.67 | 3.33 | 3.5 |
| command2 | 2.67 | 3.67 | 4 | 3.83 | 3.83 |
| command3 | 2 | 4 | 4 | 3.33 | 3.33 |
| command4 | 2.17 | 4 | 4 | 3 | 3.5 |
| command5 | 3 | 4 | 4 | 3.5 | 3.33 |
| Average | 2.47 | 3.83 | 3.93 | 3.40 | 3.50 |
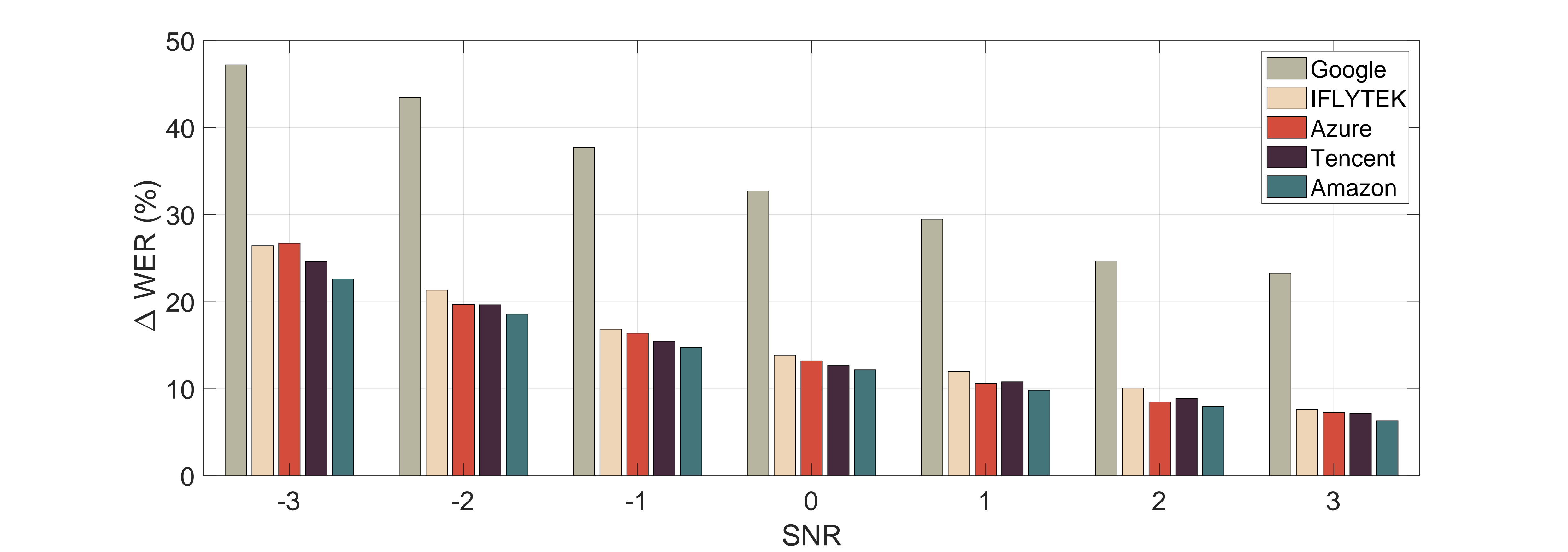
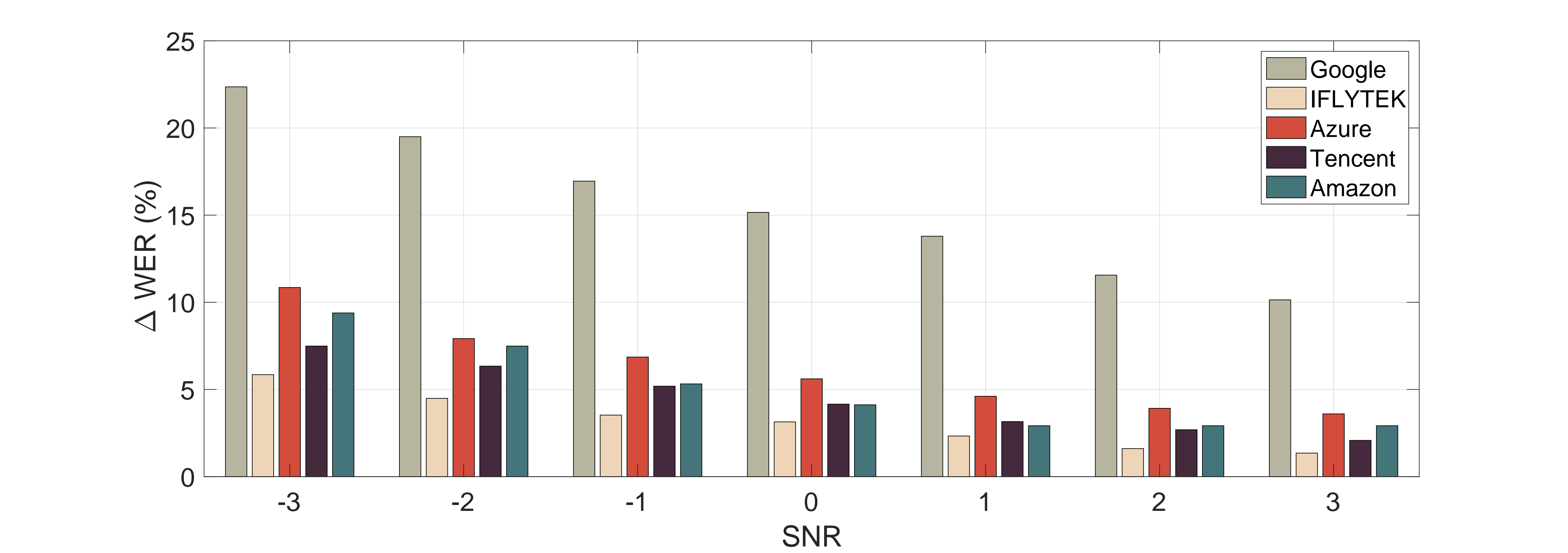
We utilize 200 event noise instances to evaluate the ASRs' robustness, resulting in a similar result to the white noise case. Google is the most vulnerable one.
We choose 10 new commands ("Clear notification", "Play music", "What's the weather", "Take a picture", "Where is my car",
"Tell me a story", "How old are you", "Sing me happy birthday", "Good morning", "Where is my home") and generate the attack
examples under the setting of α=0.3, β=22Hz, γ=1 and η=0.1 (η is only for OTA examples).
Then we attack APIs (Amazon, Azure, iFLYTEK, and Tencent) in the digital domain and attack voice assistants (Amazon Echo and Microsoft Cortana) over the air, and the results are shown below. Attacks belonging to the xxx-online and xxx-offline columns are digital-domain attacks. Attacks belonging to the Echo and Cortana column are over-the-air (OTA) attacks. Commands used in OTA attacks are generated with the online method.
★ Note: The online terminology (generating one command requires at most 50 queries) means in the iterating progress of command generation, we inquire about the target API with the audio given a new smaller loss is obtained. In contrast, the offline terminology (generating one command requires only 1 query) means we only query the API once at the last iteration round during command generation to check whether it is valid.
| Amazon-online | Amazon-offline | Azure-online | Azure-offline | iFLYTEK-online | iFLYTEK-offline | Tencent-online | Tencent-offline |
| 10/10 | 2/10 | 10/10 | 2/10 | 10/10 | 3/10 | 10/10 | 4/10 |
| Echo | Cortana |
| 10/10 | 5/10 |
We assess the impact of ambient noise, revealing that our examples perform well at an SNR of ~20, akin to soft speech, but decline with higher ambient noise. ( α=0.3, β=22Hz, γ=1 and η=0.1, distence between the speaker (Marshall) and the VA is 15 cm)
| Voice assistants | SNR~37 | SNR~25 | SNR~13 | SNR~3 |
| Echo | 6/7 | 6/7 | 3/7 | 3/7 |
| Cortana | 7/7 | 5/7 | 3/7 | 2/7 |
In addition to the downsampling method presented in the paper, we conduct further tests on the other three possible defense methods: applying a 4000Hz low-pass filter, a 5000Hz low-pass filter, and a 500 Hz high-pass filter to the audio. The results in the following table show that all these three methods can effectively defend against our attack. Specifically, the 500Hz high-pass filter exhibits the best performance, with only 1, 3, 2, and 0 attack commands being accurately recognized by the corresponding ASR.
| Defense method | Amazon | Azure | Tencent | IFLYTEK |
| High-Pass Filter: 500Hz | 1/12 | 3/10 | 2/11 | 0/11 |
| Low-Pass Filter: 4000Hz | 1/12 | 5/10 | 3/11 | 3/11 |
| Low-Pass Filter: 4000Hz | 2/12 | 5/10 | 4/11 | 5/11 |
© 2024 The State Key Laboratory of Blockchain and Data Security, Zhejiang University | Licensed under the Apache License, Version 2.0